")
Moving data from your operational database has traditionally meant setting up and monitoring a pipeline for each source to each destination. For most teams, this is a brittle, ungoverned, and O(n) human effort.
Today, we’re changing this approach. Available now in Public Preview, Lakebase features a Change Data Feed (CDF) that is stored and governed in Unity Catalog Managed Tables. Enable the feed once and allow all engines, models, and agents to read from it directly.
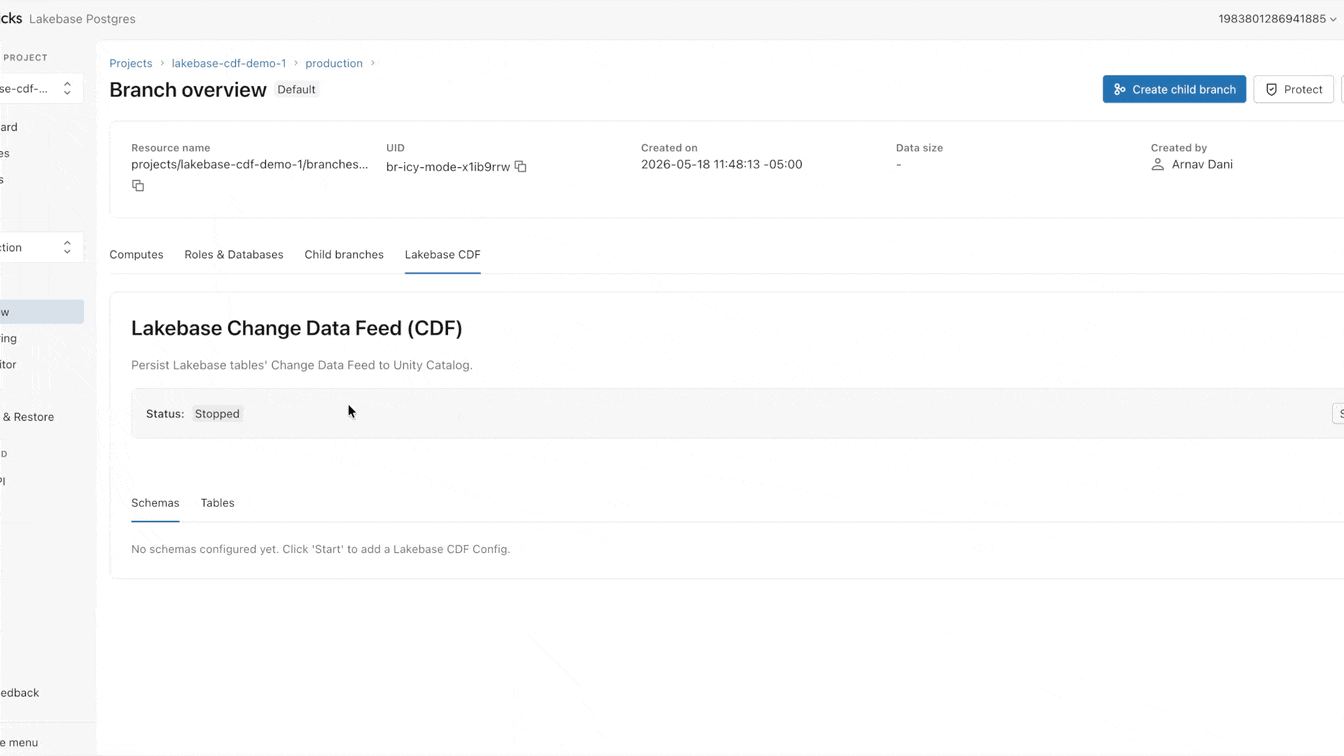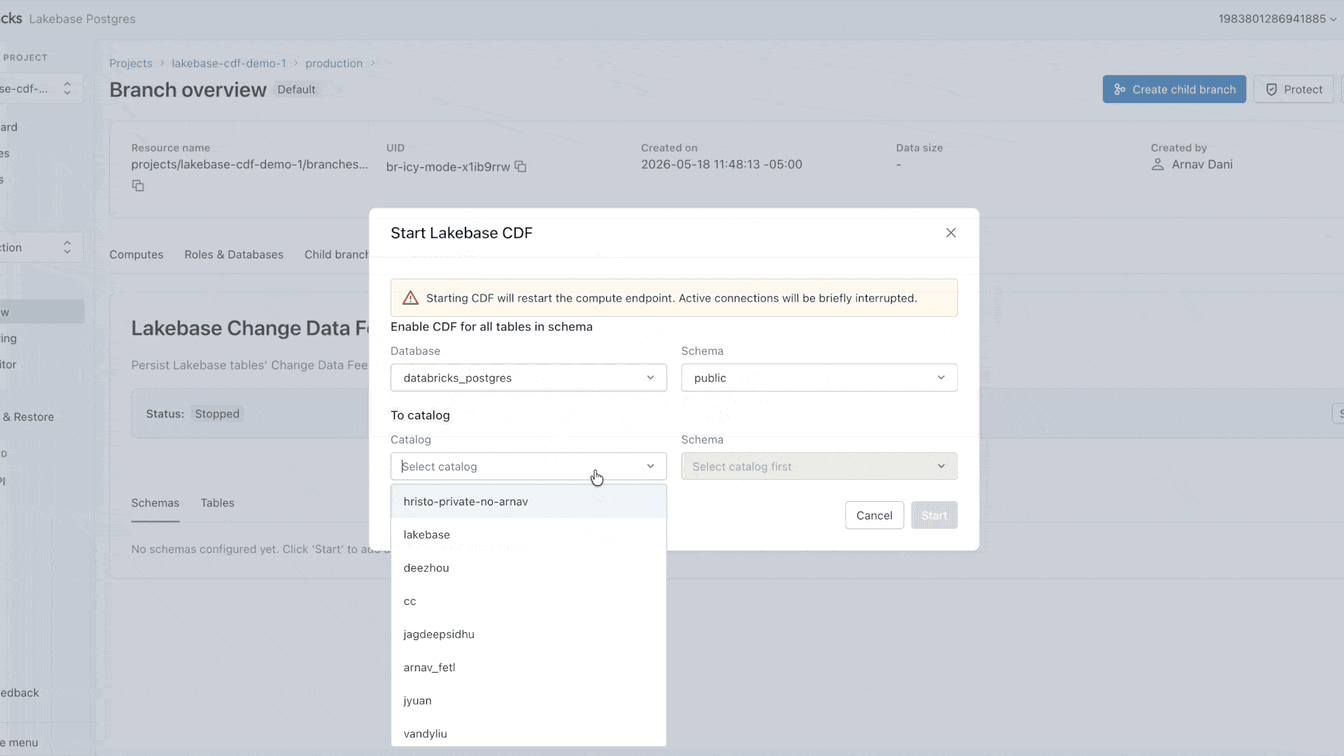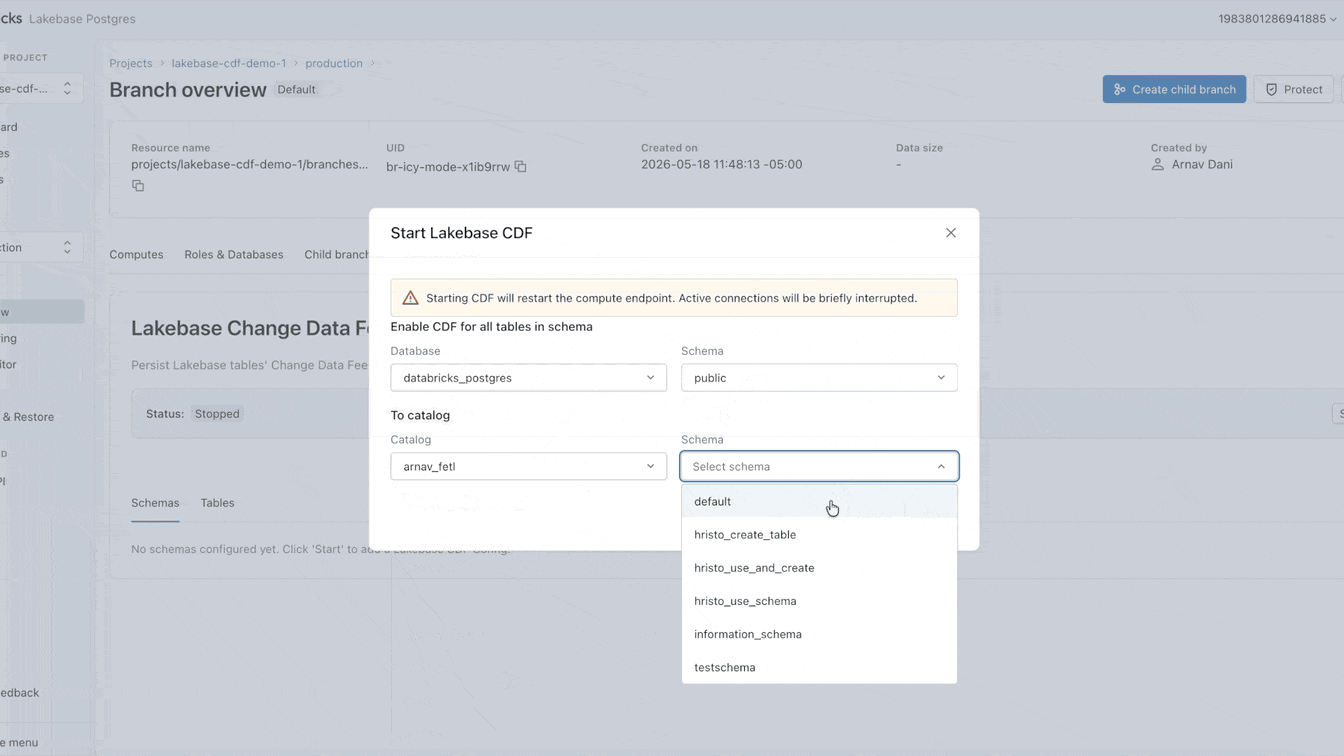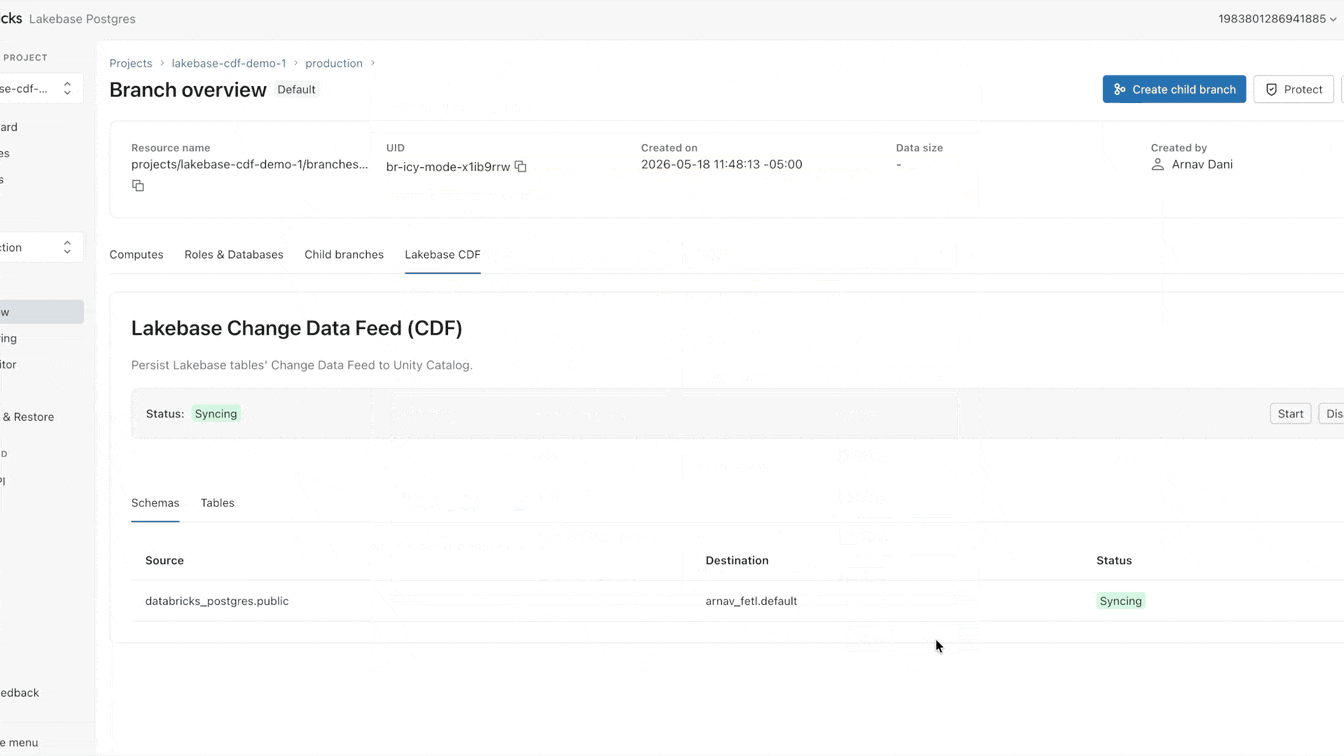
Why is landing operational data into the lake still so hard?
While Lakeflow Connect has made ingesting data into the Lakehouse trivial, getting data out of the OLTP database is remains a manual and high-friction process. Extracting Change Data Capture (CDC) forces teams to configure database connectors, babysit replication states, mitigate performance impacts, and track errors through disconnected tools. This model breaks down in agent-first development that relies on rapid data branching. Maintaining complex, ungoverned extraction pipelines for every new branch to every destination is unsustainable.
We solved this in the Lakehouse. Now we’re bringing it to Lakebase.
The Lakehouse eliminated extraction pipelines for analytics by storing data once in open formats (Apache Iceberg™, Delta Lake). It established Change Data Feed (CDF) as the standard for downstream replication, powering ETL, streaming workflows, and audit logs.
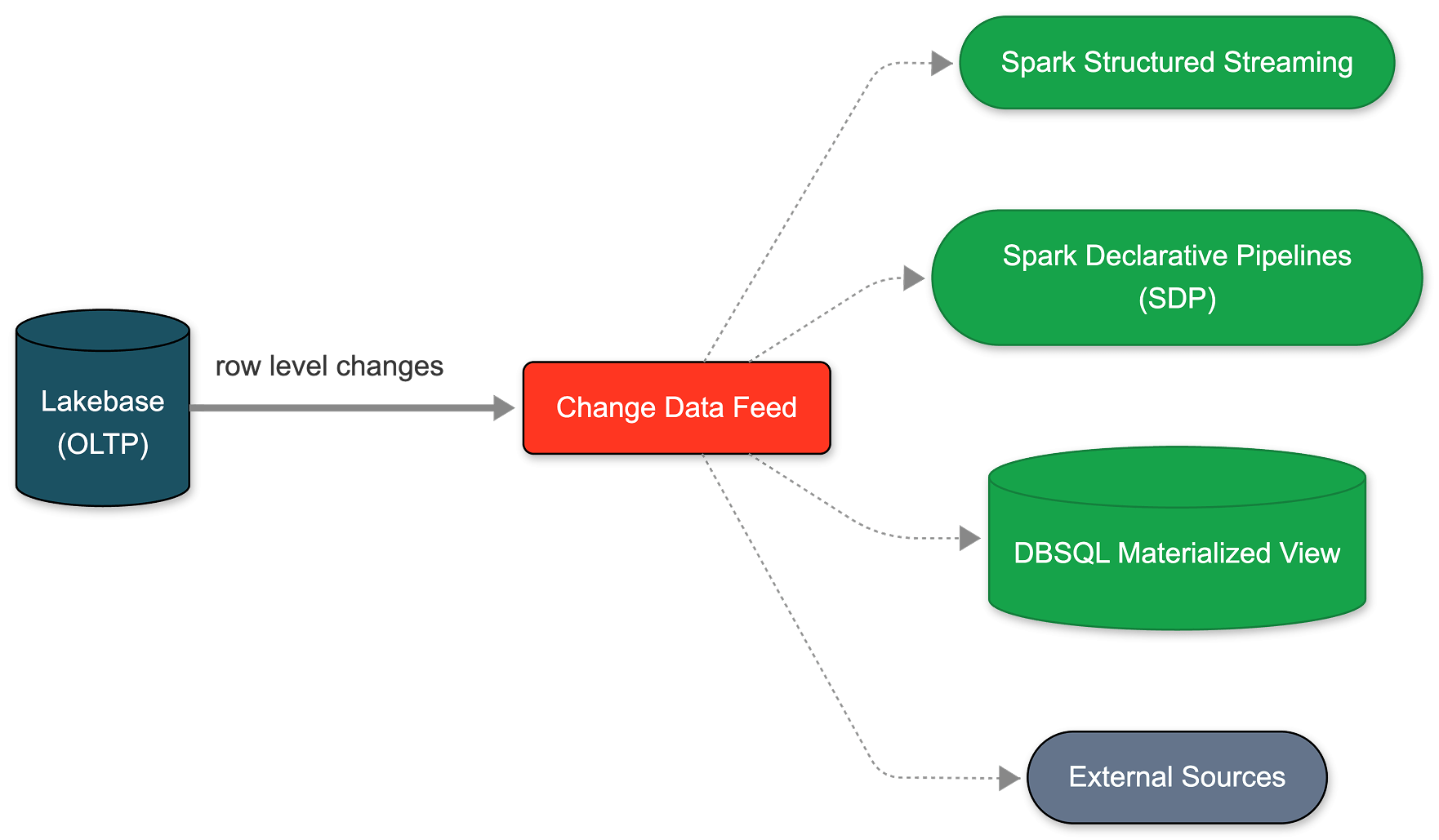
You can now set up that CDF natively on Lakebase. It takes less than a minute to enable, applying to all tables within a project. From this single feed, you can build streaming pipelines with SDP, generate materialized views with DBSQL, or compute and store embeddings with AgentBricks. Every downstream consumer subscribes to the exact same feed, completely isolated from your primary operational workload.
Operational databases belong in the medallion architecture
Your operational data is no longer isolated from the Lakehouse. Synced Tables established the pattern of serving Gold datasets directly to applications.
Lakebase CDF completes the architecture. Your operational database is now your native Bronze layer, eliminating the need for separate pipelines or extraction jobs to land data into the Lakehouse. Instead, you get full governance and lineage across the data life cycle through Unity Catalog.
This is just the start. We are bringing the openness you love from the Lakehouse directly to Lakebase. Stay tuned for Data and AI Summit, and join our breakout session on this architecture: Zero-ETL was just the start: Operational Databases belong in the Medallion Architecture.