
The FY26 National Defense Authorization Act (NDAA) underscores the importance of military training to ensure a ready and capable force. The Department of Labor’s 2025 report, America’s Talent Strategy, similarly highlights the need to leverage innovative technologies to develop the next-generation workforce. A consistent theme across these and other strategy documents is that emerging technologies have the potential to transform how people are trained and educated. We explore here the use of extended reality (XR) as a potentially transformative training technology. XR can immerse individuals in virtual environments (virtual reality, or VR) or overlay digital elements onto the real world (augmented reality, or AR). Empirical studies have demonstrated the effectiveness of XR for training cognitive, perceptual, and motor skills. Additionally, XR is less expensive than live training and may be the only safe option in many cases. Accordingly, private sector companies, along with the federal government, have made significant investments in XR.
However, while technologies for delivering virtual content have advanced rapidly, content creation is still extremely costly and time consuming. For example, it may cost $100,000 and take up to a year to develop custom VR trainings. VR pipelines involve multiple stages, and asset creation alone can require two or three months or more depending on the asset’s complexity and overall need. In essence, the technology for delivering virtual content has progressed faster than the technology for creating it. This makes it difficult to deliver XR training at scale and impossible to deliver tailored content at the time and point of need.
In this blog post, we describe a cutting-edge method for creating digital models of the physical world called 3D Gaussian Splatting (3DGS). 3DGS captures the richness of real-world geometry, texture, and lighting directly from ordinary images or video data. The result is photorealistic 3D models of objects or scenes that people can interact with in real-time. We then describe how 3DGS can be incorporated into a production pipeline that enables anyone, anywhere, to create high fidelity digital models at any time.
Innovations in 3D Modeling and Simulation
Over the past five decades, 3D modeling methods have evolved dramatically. Early approaches, known as structure-to-appearance, focused on representing an object’s geometry as a collection of linked vertices that form surfaces. These early 3D modeling methods built the object’s shape first, and then the same methods are used to apply color and textures to the surfaces to make them look realistic. Common techniques for capturing or constructing structure from physical objects include LiDAR, photogrammetry, and CAD/manual modeling.
More recently, volume-to-appearance methods, which represent scenes as continuous 3D volumes, have emerged as an alternative for 3D modeling and rendering. They build a model of color and transparency at each point in the 3D space and composite this information along different viewpoints to render realistic images. While geometry can be recovered from the volumetric representation, it is not explicitly used for rendering appearance. Popular volume-to-appearance methods include neural radiance fields (NeRF) and 3D Gaussian Splatting (3DGS). The Neural Radiance Field (NeRF) method reconstructs 3D geometry and appearance implicitly by training a neural network to match rendered rays to input data. As 3DGS intakes data and represents a scene by a cloud of splattable gaussian primitives that are optimized to render high quality novel views.

Figure 1: Diagram shows sets of 3D modeling methods. Volume to appearance, which evolved out of the traditional structure-to-appearance method, uses 3DGS or NeRF to represent scenes as continuous 3D volumes.
Volumetric methods have become the dominant approach because they model scenes as continuous fields rather than discrete surfaces, allowing them to capture complex lighting, transparency, and fine-grained detail that traditional structure-based methods cannot. Among these methods, 3DGS has become extremely popular because it delivers efficient, real-time photorealistic rendering using trainable gaussians. These properties are essential for VR, various 3D modeling applications, and the digital entertainment ecosystem.
How 3DGS Works
3DGS begins with multiple ordinary images of an object or scene captured from different angles. During training, it learns to represent the scene with tiny translucent 3D blobs called Gaussians. Each Gaussian has a defined position, scale, rotation, color, and opacity. One can think of Gaussians as droplets of paint. When the droplets are combined, they reproduce the appearance of the scene from original and novel viewpoints.
The following text box contains a technical deep dive into our algorithmic workflow for creating 3DGS models from pictures and video.
Creating 3DGS Models: A 5-Step Process
- Image Alignment
- Input video frames or photographs are processed using Structure-from-Motion (SM) to estimate camera poses.
- StM produces calibrated camera intrinsics (e.g., focal length and principal point), camera extrinsics (e.g., pose in world coordinates), and a sparse 3D point cloud corresponding to distinctive scene features.
- Gaussian Initialization from the Sparse Point Cloud
- Each point in the sparse reconstruction is initialized as a 3D Gaussian primitive.
- Each Gaussian is parameterized by an initial 3D position, covariance (scale), color (RGB), and opacity.
- Gradient Descent Optimization
- The Gaussian parameters are optimized using gradient descent to minimize the difference between rendered images and the original input views.
- During training, the scene is rendered from each known camera viewpoint, and gradients are computed to reduce pixel-level differences between the rendered and ground-truth images.
- Intuitively, the optimization approach adjusts each Gaussian’s attributes to better explain the observed appearance of the scene across all views.
- Adaptive Refinement
- Because different regions of the scene require different levels of detail, adaptive refinement strategies dynamically modify the Gaussian set during training. This involves adding, removing, splitting, or merging Gaussians that make up the model.
- This adaptive process increases detail in complex regions of the scene while maintaining efficiency elsewhere.
- Final Rendering
- The optimized Gaussians are splatted and accumulated in screen space to produce high-fidelity renderings from arbitrary viewpoints.
- This representation enables high-quality, real-time novel-view synthesis.
A User-Centered Pipeline for Creating Digital Models of the Physical World
A team of researchers in the SEI’s CERT Division is developing an end-to-end pipeline that enables users anywhere to create 3DGS models. The pipeline begins with on-demand data collection, supporting both large scenes and detailed objects. It then applies state-of-the-art algorithms to generate high-fidelity digital models. Finally, the resulting digital model is rendered in multiple ways that can be tailored to specific mission needs. The figure below provides a visual overview of the pipeline, along with a detailed breakdown of each key step.
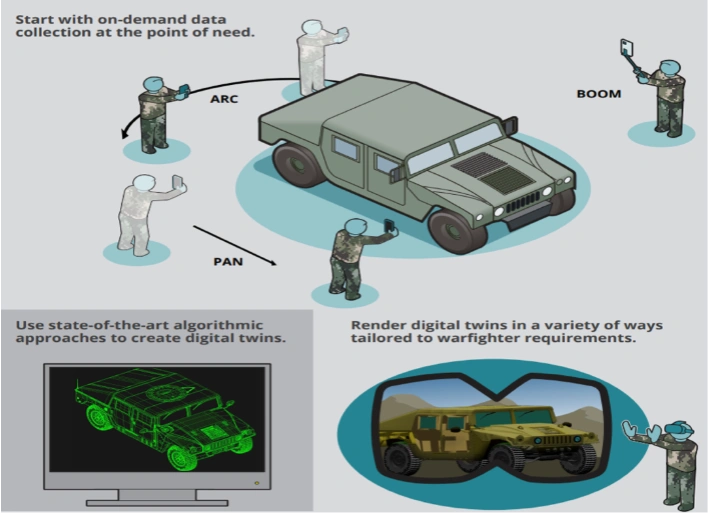
Figure 2: On-demand field data collection enables rapid creation and visualization of scene or object digital twins for a requirement.
Step 1. On-demand data collection. Our user-centered pipeline begins with on-demand data collection. A user equipped with a mobile camera can walk around a large object, like a truck, to capture images from multiple angles. Alternatively, a shoulder or vehicle-mounted 360-degree camera rig can be used to collect data from large indoor or outdoor scenes.
For small objects, a different process is used to create high-fidelity models. In this case, the object is placed on a turntable inside a light tent. A microcontroller rotates the turntable in small increments while coordinating a camera array to capture images after each rotation. This setup enables precise image acquisition from multiple viewpoints in an automated manner.

Together, these data-collection approaches allow users to capture imagery across a wide range of scales ranging from city blocks to pocket-sized objects. As in the above image, one can see imagery of a small terrain vehicle from the on-demand data collection process.
Step 2. Model creation. In this step, images and video are processed using a suite of algorithmic methods to generate visual digital twins that capture geometric structure and visual appearance. We begin by applying Structure-from-Motion (SfM) pipelines—including COLMAP, GLOMAP, and FASTMAP—to image datasets to estimate camera intrinsics, extrinsics, and scene geometry. GLOMAP and FASTMAP are variants of COLMAP which is a widely used structure-from-motion pipeline. This all ends in resulting imagery, camera parameters, and geometric information are then provided as inputs to 3DGS methods, such as gsplat and MeshSplatting, to train high-fidelity 3DGS models.

To support scalable and reproducible model generation, all software components are containerized using Docker and orchestrated through automated pipeline workflows. This design enables deployment of the complete software stack in on-premises or cloud environments. As an example, during model creation one can see the gaussians being developed in the below image. These gaussians hold the shape of ellipsoids.
Step 3. Model deployment. Following model development, digital assets can be rendered in a variety of ways depending on mission need. For example, models can be embedded in a game engine to create playable 2D scenes on a tablet or computer, or immersive 3D scenes in VR. Additionally, digital assets can be hosted in a cloud environment and accessed through a web-based viewer for interactive use. Separately, geometry can be extracted from 3DGS models to create and print geometrically accurate 3D-printed props. The image below depicts a digital asset from this process.

Real-world 3DGS Use Cases
To demonstrate the utility of 3DGS, we present two hypothetical scenarios that reflect the types of real-world use cases that we are currently developing.
- Aviation Maintenance Training: At a forward-deployed location, an aircraft maintenance training manager wants to create digital replicas and physical training aids that allow inexperienced maintainers to practice servicing engine components without risking damage to operational parts. Currently, there is no effective way to generate such training resources at the time and point of need.
Using our system, the training manager can capture datasets of individual aircraft components using the portable light table and upload the data to the pipeline to generate high-fidelity digital models of objects within minutes to hours. Once a digital model is complete, the trainer can select the best rendering modality to support the training objective. For example, the model can be shared through a web-based interactive viewer, allowing students to inspect and manipulate the part virtually. Alternatively, a geometric model can be extracted from the digital asset and used to produce a 3D-printed physical replica of the part for hands-on training.
- Emergency Response Damage Assessment: Following a natural disaster, emergency responders must rapidly survey affected areas and develop safe and effective recovery plans. At present, this assessment is typically based on incomplete 2D imagery collected from low-altitude drones, satellites, and other standoff sensing platforms, which can limit situational awareness.
Using our system, emergency responders can deploy a fleet of drones to systematically survey routes, infrastructure damage, and environmental hazards across the disaster site. The collected data are uploaded to the pipeline to generate high-fidelity digital models of the scene within hours. Once the digital model is complete, responders can select the rendering modality best suited to support recovery operations. For example, the model can be visualized in an interactive 2D game-engine environment on a tablet or rendered as an immersive 3D experience using a VR headset. These capabilities enable responders to analyze conditions, rehearse response strategies, and coordinate operations prior to on-site deployment.
Partner With Us
Training and education are essential to develop and sustain our mission workforce. XR is a potentially transformative training technology, yet the time and cost to create digital assets for use in XR have limited its use. Volumetric reconstruction techniques—namely, 3DGS—can greatly reduce these barriers.
Here at the SEI, we have developed an end-to-end pipeline to capture data, create 3DGS models, and deploy those models in a variety of forms. We are ready to share our experiences and lessons learned. The SEI is actively searching for potential collaborators in this area. Any interested parties looking to further the mission in this research space should inquire at info@sei.cmu.edu.