
This blog was written in collaboration with Fan Bu, Jason Mackay, Borya Sobolev, Dev Khanolkar, Ali Dabir, Puneet Kamal, Li Zhang, and Lei Jin.
“Everything is a file”; some are databases
Introduction
Machine data underpins observability and diagnosis in modern computing systems, including logs, metrics, telemetry traces, configuration snapshots, and API response payloads. In practice, this data is embedded into prompts to form an interleaved composition of natural-language instructions and large machine-generated payloads, typically represented as JSON blobs or Python/AST literals. While large language models excel at reasoning text and code, they frequently struggle with machine-generated sequences – particularly when those are long, deeply nested, and dominated by repetitive structure.
We repeatedly observe three failure modes:
- Token explosion from verbosity: Nested keys and repeated schema dominate the context window, fragmenting the data.
- Context rot: The model misses the “needle” hidden inside large payloads and drifts from the instruction.
- Weakness on numeric/categorical sequence reasoning: Long sequences obscure patterns such as anomalies, trends, and entity relationships.The bottleneck isn’t simply about the length of the inputs. Machine data instead requires structural transformation and signal enhancement so that the same information is presented in representations aligned with a model’s strengths.
“Everything is a file”; some are databases
Anthropic successfully popularized the notion that “bash is all you need” for agentic workflows, especially for vibe coding, by fully leveraging the file system and composable bash tools. In machine-data-heavy settings of context engineering, we argue that principles from database management apply: rather than forcing the model to process raw blobs directly, full-fidelity payloads could be stored in a datastore, allowing the agent to query them and generate optimized hybrid data views that align with the LLM’s reasoning strengths using a subset of simple SQL statements.
Hybrid data views for machine data – “simple SQL is what you need”
These hybrid views are inspired by the database concept of hybrid transactional/analytical processing (HTAP), where different data layouts serve different workloads. Similarly, we maintain hybrid representations of the same payload so that different portions of the data can be more effectively understood by the LLM.
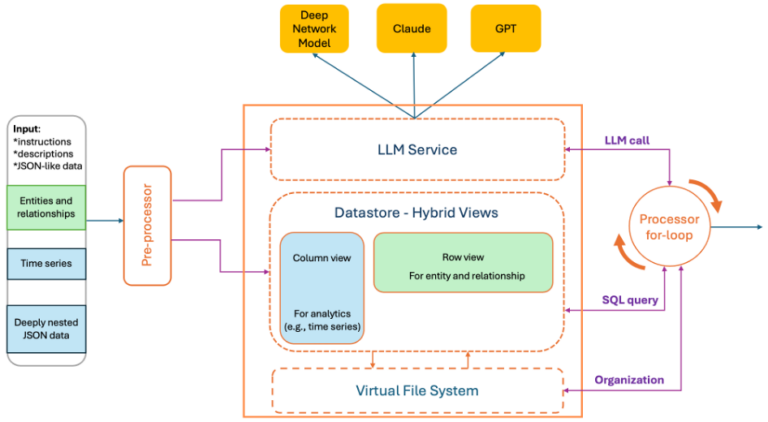
To this end, we introduce ACE (Analytics Context Engineering) for machine data—a framework for constructing and managing analytics context for LLMs. ACE combines a virtual file system (mapping observability APIs to files and transparently intercepting Bash tools to avoid unscalable MCP calls) with the simplicity of Bash for intuitive, high-level organization, while incorporating database-style management techniques to enable precise, fine-grained control over low-level data entries.
Deep Network Model – ACE
ACE is used in Cisco AI Canvas runbook reasoning. It converts raw prompts and machine payloads into hybrid views in instruction-preserving contexts that LLMs can reliably consume. ACE was initially designed to enhance the Deep Network Model (DNM), a Cisco purpose-built LLM for networking domains. To support a broader range of LLM models, ACE was subsequently implemented as a standalone service.
At a high level:
- A preprocessor parses the user prompt—comprising natural language and embedded JSON/AST blobs as a single string—and produces hybrid data views along with optional language summaries (e.g., statistics or anomaly traces), all within a specified token budget.
- A datastore keeps a full-fidelity copy of the original machine data. This allows the LLM context to remain small while still enabling complete answers.
- A processor for-loop inspects the LLM output and conditionally queries the datastore to enrich the response, producing a complete, structured final response.
Row-oriented + Columnar views
We generate complementary representations of the same payload:
- Columnar view (field-centric). For analytics tasks (e.g., line/bar chart, trend, pattern, anomaly detection), we transform nested JSON into flattened dotted paths and per-field sequences. This eliminates repeated prefixes, makes related data contiguous, and eases the computation per field.
- Row-oriented view (entry-centric). To support relationship reasoning — such as has-a and is-a relationships, including entity membership and association mining — we provide a row-oriented representation that preserves record boundaries and local context across fields. Because this view does not impose an inherent ordering across rows, it naturally enables the application of statistical methods to rank entries by relevance. Specifically, we design a modified TF-IDF algorithm, based on query relevance, word popularity, and diversity, to rank rows.
Rendering format: We provide multiple formats for rendering content. The default format remains JSON; although it is not always the most token-efficient representation, our experience shows that it tends to work best with most existing LLMs. In addition, we offer a customized rendering format inspired by the open-source TOON project and Markdown, with several key differences. Depending on the schema’s nesting structure, data are rendered either as compact flat lists with dotted key paths or using an indented representation. Both approaches help the model infer structural relationships more effectively.
The concept of a hybrid view is well established in database systems, particularly in the distinction between row-oriented and column-oriented storage, where different data layouts are optimized for different workloads. Algorithmically, we construct a parsing tree for each JSON/AST literal blob and traverse the tree to selectively transform nodes using an opinionated algorithm that determines whether each component is better represented in a row-oriented or columnar view, while preserving instruction fidelity under strict token constraints.
Design principle
- ACE follows a principle of simplicity, favoring a small set of generic tools. It embeds analytics directly into the LLM’s iterative reasoning-and-execution loop, using a restricted subset of SQL together with Bash tools over a virtual file system as the native mechanisms for data management and analytics.
- ACE prioritizes context-window optimization, maximizing the LLM’s reasoning capacity within bounded prompts while maintaining a complete copy of the data in an external datastore for query-based access. Carefully designed operators are applied to columnar views, while ranking methods are applied to row-oriented views.
In production, this approach drastically reduces prompt size, cost, and inference latency while improving answer quality.
Illustrative examples
We evaluate token usage and answer quality (measured by an LLM-as-a-judge reasoning score) across representative real-world workloads. Each workload comprises independent tasks corresponding to individual steps in a troubleshooting workflow. Because our evaluation focuses on single-step performance, we do not include full agentic diagnosis trajectories with tool calls. Beyond significantly reducing token usage, ACE also achieves higher answer accuracy.
1. Slot filling:
Network runbook prompts combine instructions with JSON-encoded board and chat state, prior variables, tool schemas, and user intent. The task is to surface a handful of fields buried in dense, repetitive machine payloads.
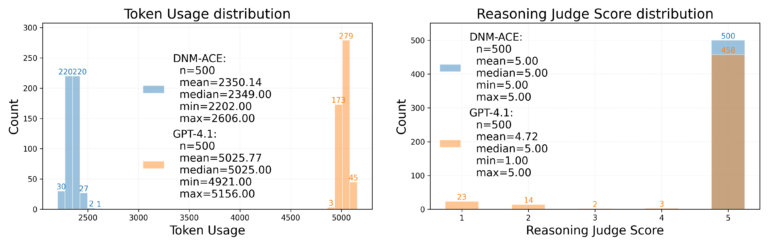
Our approach reduces the average token count from 5,025 to 2,350 and corrects 42 errors (out of 500 tests) compared to directly calling GPT-4.1.
2. Anomalous behaviors:
The task is to handle a broad spectrum of machine data analysis tasks in observability workflows.
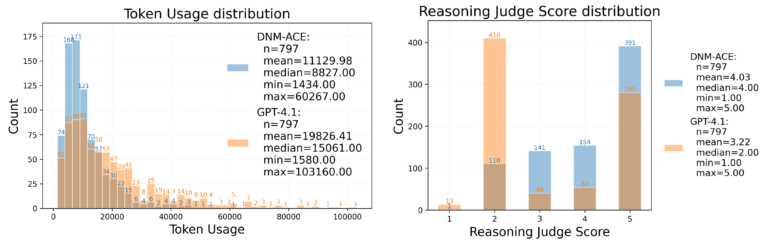
By applying anomaly detection operators to columnar views to provide additional contextual information, our approach increases the average answer quality score from 3.22 to 4.03 (out of 5.00), a 25% increase of accuracy, while achieving a 44% reduction in token usage across 797 samples.
3. Line chart:
The input typically consists of time-series metrics data that are arrays of measurement records collected at regular intervals. The task is to render this data using frontend charting libraries.
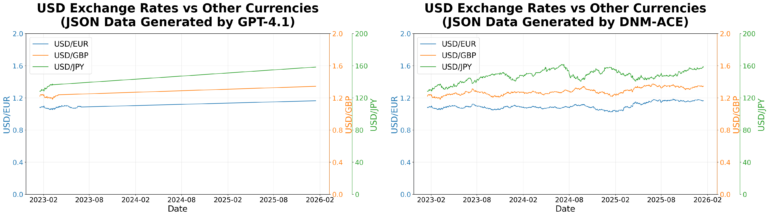
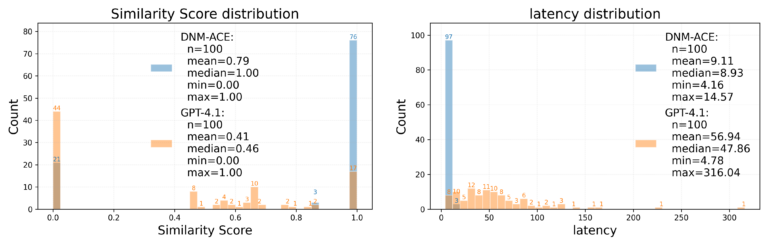
Directly calling the LLM often results in incomplete data rendering due to long output sequences, even when the input fits within the context window. In the figure above, LLM produces a line chart with only 40-120 points per series instead of the expected 778, leading to missing data points. Across 100 test samples, as shown in the following two figures, our approach achieves approximately 87% token savings, reduces average end-to-end latency from 47.8 s to 8.9 s, and improves the answer quality score (similarity_overall) from 0.410 to 0.786 (out of 1.00).
4. Benchmark summary:
In addition to the three examples discussed above, we compare key performance metrics across a wide range of networking-related tasks in the following table.
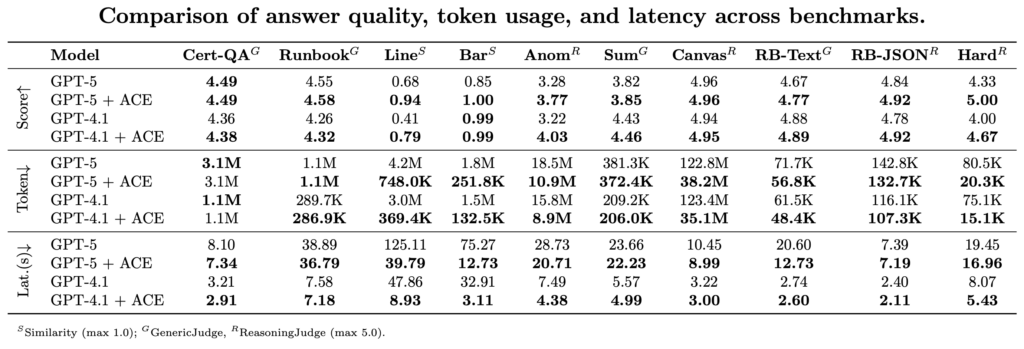
Observations: Extensive testing across a wide range of benchmarks demonstrates that ACE reduces token usage by 20–90% depending on the task, while maintaining and in many cases improving answer accuracy. In practice, this effectively delivers an “unlimited” context window for prompts involving machine data.
The above evaluation covers only individual steps within an agentic workflow. Design principles grounded in a virtual file system and database management enable ACE to interact with the LLM’s reasoning process by extracting salient signals from the vast volume of observability data through multi-turn interactions.