The discourse about to what level AI-generated code should be reviewed often feels very binary. Is vibe coding (i.e. letting AI generate code without looking at the code) good or bad? The answer is of course neither, because “it depends”.
So what does it depend on?
When I’m using AI for coding, I find myself constantly making little risk assessments about whether to trust the AI, how much to trust it, and how much work I need to put into the verification of the results. And the more experience I get with using AI, the more honed and intuitive these assessments become.
Risk assessment is typically a combination of three factors:
- Probability
- Impact
- Detectability
Reflecting on these 3 dimensions helps me decide if I should reach for AI or not, if I should review the code or not, and at what level of detail I do that review. This also helps me think about mitigations I can put in place when I want to take advantage of AI’s speed, but reduce the risk of it doing the wrong thing.
1. Probability: How likely is AI to get things wrong?
The following are some of the factors that help you determine the probability dimension.
Know your tool
The AI coding assistant is a function of the model used, the prompt orchestration happening in the tool, and the level of integration the assistant has with the codebase and the development environment. As developers, we don’t have all the information about what is going on under the hood, especially when we’re using a proprietary tool. So the assessment of the tool quality is a combination of knowing about its proclaimed features and our own previous experience with it.
Is the use case AI-friendly?
Is the tech stack prevalent in the training data? What is the complexity of the solution you want AI to create? How big is the problem that AI is supposed to solve?
You can also more generally consider if you’re working on a use case that needs a high level of “correctness”, or not. E.g., building a screen exactly based on a design, or drafting a rough prototype screen.
Be aware of the available context
Probability isn’t only about the model and the tool, it’s also about the available context. The context is the prompt you provide, plus all the other information the agent has access to via tool calls etc.
-
Does the AI assistant have enough access to your codebase to make a good decision? Is it seeing the files, the structure, the domain logic? If not, the chance that it will generate something unhelpful goes up.
-
How effective is your tool’s code search strategy? Some tools index the entire codebase, some make on the fly
grep-like searches over the files, some build a graph with the help of the AST (Abstract Syntax Tree). It can help to know what strategy your tool of choice uses, though ultimately only experience with the tool will tell you how well that strategy really works. -
Is the codebase AI-friendly, i.e. is it structured in a way that makes it easy for AI to work with? Is it modular, with clear boundaries and interfaces? Or is it a big ball of mud that fills up the context window quickly?
-
Is the existing codebase setting a good example? Or is it a mess of hacks and anti-patterns? If the latter, the chance of AI generating more of the same goes up if you don’t explicitly tell it what the good examples are.
2. Impact: If AI gets it wrong and you don’t notice, what are the consequences?
This consideration is mainly about the use case. Are you working on a spike or production code? Are you on call for the service you are working on? Is it business critical, or just internal tooling?
Some good sanity checks:
- Would you ship this if you were on call tonight?
- Does this code have a high impact radius, e.g. is it used by a lot of other components or consumers?
3. Detectability: Will you notice when AI gets it wrong?
This is about feedback loops. Do you have good tests? Are you using a typed language? Does your stack make failures obvious? Do you trust the tool’s change tracking and diffs?
It also comes down to your own familiarity with the codebase. If you know the tech stack and the use case well, you’re more likely to spot something fishy.
This dimension leans heavily on traditional engineering skills: test coverage, system knowledge, code review practices. And it influences how confident you can be even when AI makes the change for you.
A combination of traditional and new skills
You might have already noticed that many of these assessment questions require “traditional” engineering skills, others

Combining the three: A sliding scale of review effort
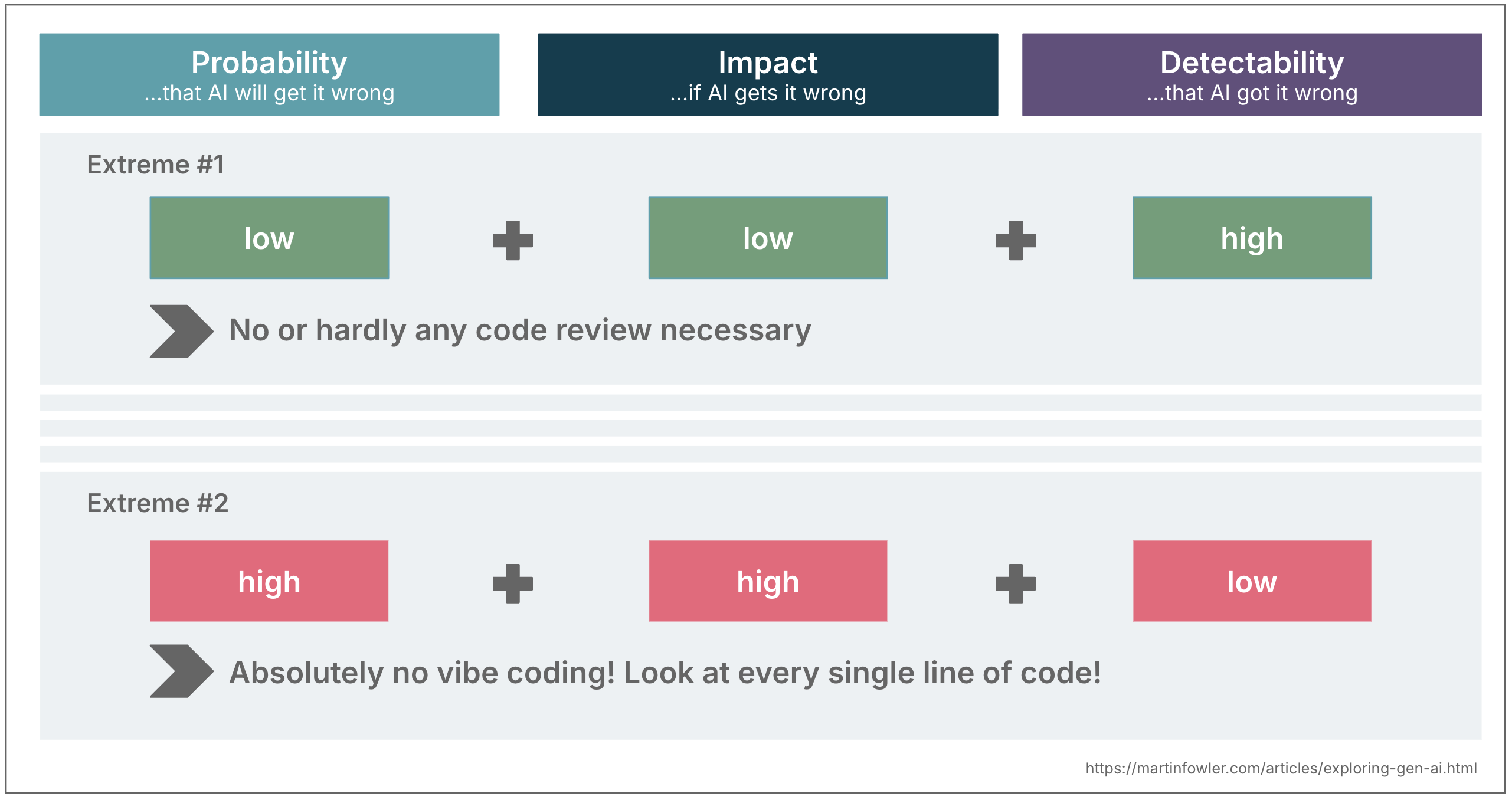
When you combine these three dimensions, they can guide your level of oversight. Let’s take the extremes as an example to illustrate this idea:
- Low probability + low impact + high detectability Vibe coding is fine! As long as things work and I achieve my goal, I don’t review the code at all.
- High probability + high impact + low detectability High level of review is advisable. Assume the AI might be wrong and cover for it.
Most situations land somewhere in between of course.
Example: Legacy reverse engineering
We recently worked on a legacy migration for a client where the first step was to create a detailed description of the existing functionality with AI’s help.
-
Probability of getting wrong descriptions was medium:
-
Tool: The model we had to use often failed to follow instructions well
-
Available context: we did not have access to all of the code, the backend code was unavailable.
-
Mitigations: We ran prompts multiple times to spot check variance in results, and we increased our confidence level by analysing the decompiled backend binary.
-
-
Impact of getting wrong descriptions was medium
-
Business use case: On the one hand, the system was used by thousands of external business partners of this organization, so getting the rebuild wrong posed a business risk to reputation and revenue.
-
Complexity: On the other hand, the complexity of the application was relatively low, so we expected it to be quite easy to fix mistakes.
-
Planned mitigations: A staggered rollout of the new application.
-
-
Detectability of getting the wrong descriptions was medium
-
Safety net: There was no existing test suite that could be cross-checked
-
SME availability: We planned to bring in SMEs for review, and to create a feature parity comparison tests.
-
Without a structured assessment like this, it would have been easy to under-review or over-review. Instead, we calibrated our approach and planned for mitigations.
Closing thought
This kind of micro risk assessment becomes second nature. The more you use AI, the more you build intuition for these questions. You start to feel which changes can be trusted and which need closer inspection.
The goal is not to slow yourself down with checklists, but to grow intuitive habits that help you navigate the line between leveraging AI’s capabilities while reducing the risk of its downsides.