Your agents are only as good as the knowledge they can access — and only as safe as the permissions they enforce.
We’re launching ACL Hydration (access control list hydration) to secure knowledge workflows in the DataRobot Agent Workforce Platform: a unified framework for ingesting unstructured enterprise content, preserving source-system access controls, and enforcing those permissions at query time — so your agents retrieve the right information for the right user, every time.
The problem: enterprise knowledge without enterprise security
Every organization building agentic AI runs into the same wall. Your agents need access to knowledge locked inside SharePoint, Google Drive, Confluence, Jira, Slack, and dozens of other systems. But connecting to those systems is only half the challenge. The harder problem is ensuring that when an agent retrieves a document to answer a question, it respects the same permissions that govern who can see that document in the source system.
Today, most RAG implementations ignore this entirely. Documents get chunked, embedded, and stored in a vector database with no record of who was — or wasn’t — supposed to access them. This can result in a system where a junior analyst’s query surfaces board-level financial documents, or where a contractor’s agent retrieves HR files meant only for internal leadership. The challenge isn’t just how to propagate permissions from the data sources during the population of the RAG system — those permissions need to be continuously refreshed as people are added to or removed from access groups. This is critical to keep synchronized controls over who can access various types of source content.
This isn’t a theoretical risk. It’s the reason security teams block GenAI rollouts, compliance officers hesitate to sign off, and promising agent pilots stall before reaching production. Enterprise customers have been explicit: without access-control-aware retrieval, agentic AI can’t move beyond sandboxed experiments.
Existing solutions don’t solve this well. Some can enforce permissions — but only within their own ecosystems. Others support connectors across platforms but lack native agent workflow integration. Vertical applications are restricted to internal search without platform extensibility. None of these options give enterprises what they actually need: a cross-platform, ACL-aware knowledge layer purpose-built for agentic AI.
What DataRobot provides
DataRobot’s secure knowledge workflows provide three foundational, interlinked capabilities in the Agent Workforce Platform for secure knowledge and context management.
1. Enterprise data connectors for unstructured content
Connect to the systems where your organization’s knowledge actually lives. At launch, we’re providing production-grade connectors for SharePoint, Google Drive, Confluence, Jira, OneDrive, and Box — with Slack, GitHub, Salesforce, ServiceNow, Dropbox, Microsoft Teams, Gmail, and Outlook following in subsequent releases.
Each connector supports full historical backfill for initial ingestion and scheduled incremental syncs to keep your vector databases current. You control access and manage connections through APIs or the DataRobot UI.
These aren’t lightweight integrations. They’re built to handle production-scale workloads — 100GB+ of unstructured data — with robust error handling, retries, and sync status monitoring.
2. ACL Hydration and metadata preservation
This is the core differentiator. When DataRobot ingests documents from a source system, it doesn’t just extract content — it captures and preserves the access control metadata (ACLs) that define who can see each document. User permissions, group memberships, role assignments — all of it is propagated to the vector database lookup so that retrieval is aware of the permissioning on the data being retrieved.
Here’s how it works (also illustrated in Figure 1 below):
- During ingestion, document-level ACL metadata — including user, group, and role permissions — is extracted from the source system and persisted alongside the vectorized content.
- ACLs are stored in a centralized cache, decoupled from the vector database itself. This is a critical architectural decision: when permissions change in the source system, we update the ACL cache without reindexing the entire VDB. Permission changes propagate to all downstream consumers automatically. This includes permissioning for locally uploaded files, which respect DataRobot RBAC.
- Near real-time ACL refresh keeps the system in sync with source permissions. DataRobot continuously polls and refreshes ACLs within minutes. When someone’s access is revoked in SharePoint or a Google Drive folder is restructured, those changes are reflected in DataRobot on a scheduled basis — ensuring your agents never serve stale permissions.
- External identity resolution maps users and groups from your enterprise directory (via LDAP/SAML) to the ACL metadata, so permission checks resolve correctly regardless of how identities are represented across different source systems.

3. Dynamic permission enforcement at query time
Storing ACLs is necessary but not sufficient. The real work happens at retrieval time.
When an agent queries the vector database on behalf of a user, DataRobot’s authorization layer evaluates the stored ACL metadata against the requesting user’s identity, group memberships, and roles — in real time. Only embeddings the user is authorized to access are returned. Everything else is filtered before it ever reaches the LLM.
This means two users can ask the same agent the same question and receive different answers — not because the agent is inconsistent, but because it’s correctly scoping its knowledge to what each user is permitted to see.
For documents ingested without external ACLs (such as locally uploaded files), DataRobot’s internal authorization system (AuthZ) handles access control, ensuring consistent permission enforcement regardless of how content enters the platform.
How it works: step by step
Step 1: Connect your data sources
Register your enterprise data sources in DataRobot. Authenticate via OAuth, SAML, or service accounts depending on the source system. Configure what to ingest — specific folders, file types, metadata filters. DataRobot handles the initial backfill of historical content.
Step 2: Ingest content with ACL metadata
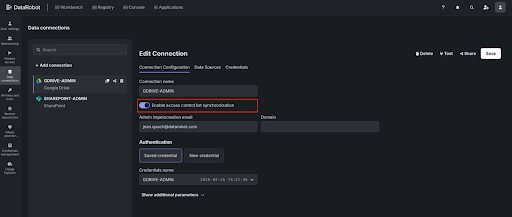
As documents are ingested, DataRobot extracts content for chunking and embedding while simultaneously capturing document-level ACL metadata from the source system. This metadata — including user permissions, group memberships, and role assignments — is stored in a centralized ACL cache.
The content flows through the standard RAG pipeline: OCR (if needed), chunking, embedding, and storage in your vector database of choice — whether DataRobot’s built-in FAISS-based solution or your own Elastic, Pinecone, or Milvus instance — with the ACLs following the data throughout the workflow.
Step 3: Map external identities
DataRobot resolves user and group information. This mapping ensures that ACL permissions from source systems — which may use different identity representations — can be accurately evaluated against the user making a query.
Group memberships, including external groups like Google Groups, are resolved and cached to support fast permission checks at retrieval time.
Step 4: Query with permission enforcement
When an agent or application queries the vector database, DataRobot’s AuthZ layer intercepts the request and evaluates it against the ACL cache. The system checks the requesting user’s identity and group memberships against the stored permissions for each candidate embedding.
Only authorized content is returned to the LLM for response generation. Unauthorized embeddings are filtered silently — the agent responds as if the restricted content doesn’t exist, preventing any information leakage.
Step 5: Monitor, audit, and govern
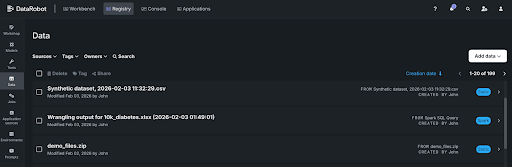
Every connector change, sync event, and ACL modification is logged for auditability. Administrators can track who connected which data sources, what data was ingested, and what permissions were applied — providing full data lineage and compliance traceability.
Permission changes in source systems are propagated through scheduled ACL refreshes, and all downstream consumers — across all VDBs built from that source — are automatically updated.
Why this matters for your agents
Secure knowledge workflows change what’s possible with agentic AI in the enterprise.
Agents get the context they need without compromising security. By propagating ACLs, agents have the context information they need to get the job done, while ensuring the data accessed by agents and end users honors the authentication and authorization privileges maintained in the enterprise. An agent doesn’t become a backdoor to enterprise information — while still having all the enterprise context needed to do its job.
Security teams can approve production deployments. With source-system permissions enforced end-to-end, the risk of unauthorized data exposure through GenAI isn’t just mitigated — it’s eliminated. Every retrieval respects the same access boundaries that govern the source system.
Builders can move faster. Instead of building custom permission logic for every data source, builders get ACL-aware retrieval out of the box. Connect a source, ingest the content, and the permissions come with it. This removes weeks of custom security engineering from every agent project.
End users can trust the system. When users know that the agent only surfaces information they’re authorized to see, adoption accelerates. Trust isn’t a feature you bolt on — it’s the result of an architecture that enforces permissions by design.
Get started
Secure knowledge workflows are available now in the DataRobot Agent Workforce Platform. If you’re building agents that need to reason over enterprise data — and you need those agents to respect who can see what — this is the capability that makes it possible. Try DataRobot or request a demo.